

Achieving 100% Automation in Transferring RDS Backups to S3 Glacier Deep Archive
RDS, S3, IAM, Lambda, KMS, SNS, EventBridge, S3 Glacier


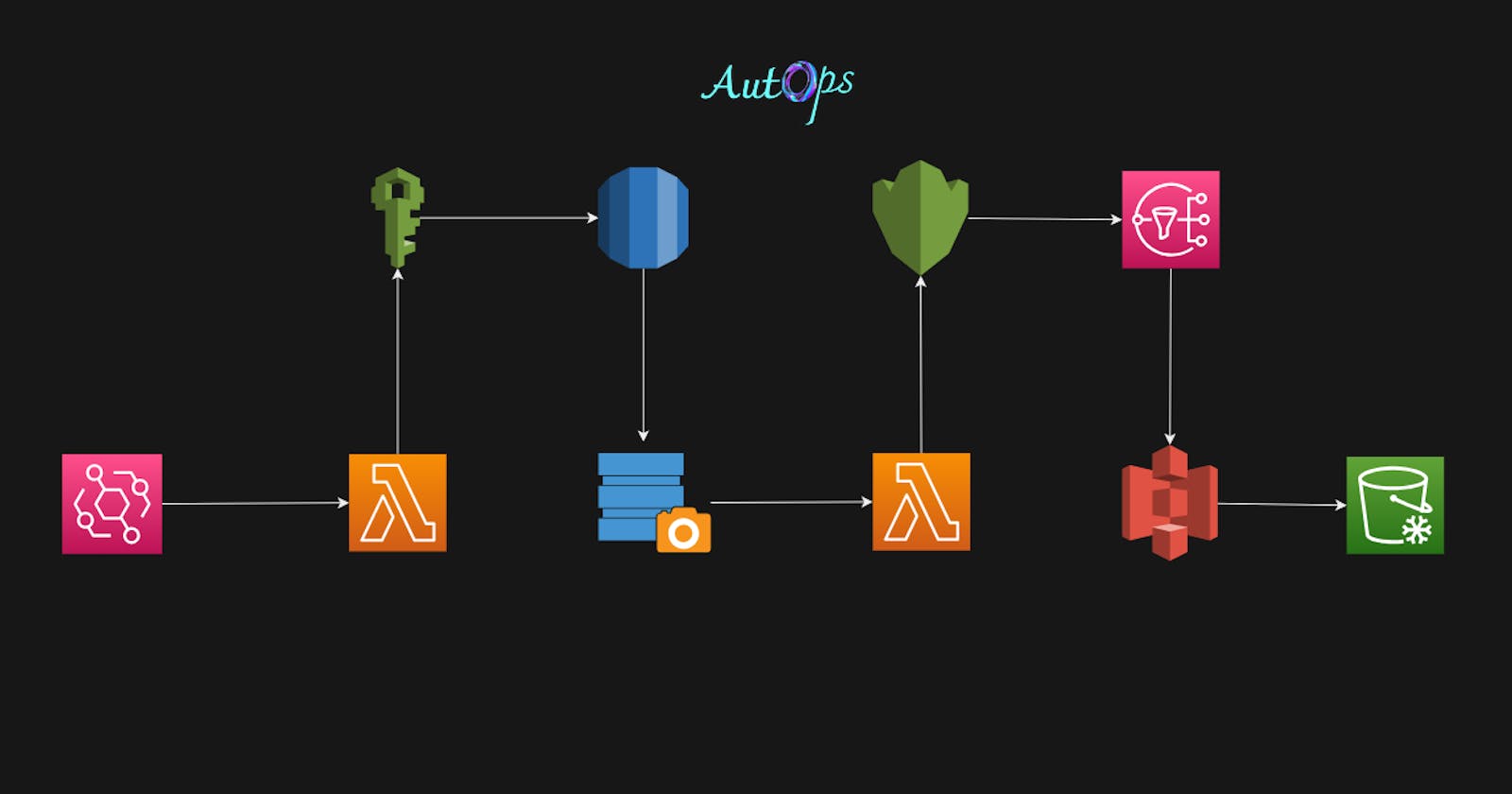
Table of contents
- Benefits Of Storing RDS Backup Data In S3 Glacier Deep Archive
- Step 1: Create S3 Bucket With Object Locks
- Step 2: Attach LIfeCycle Rule
- first, What are the lifecycle rules?
- second, What are the storage classes?
- Step 3: Create An IAM Role
- Step 4: Create KMS Key
- Step 5: Create Demo RDS Instance
- Step 6: Create a Lambda Function
- Step 7: Create SNS Topic
- Step 8: Create a Destination For Lambda
- Step 9: Create Trigger For Lambda Function
- Cron Expressions
- Rate Expressions
- Step 10: Testing Lambda Function
- Step 11: Clean Up
Benefits Of Storing RDS Backup Data In S3 Glacier Deep Archive
Cost-Effective: It provides the most economical storage currently available in the cloud.
Secure and Durable: It offers near limitless secure and durable capacity.
Long-Term Retention: It supports long-term retention and digital preservation for data that may be accessed once or twice in a year.
Fast Retrieval: It allows you to retrieve archived data in just 12 hours.
Eliminates Need for Tapes: It eliminates both the cost and management of tape infrastructure.
Easy to Manage: It is a cost-effective and easy-to-manage alternative to magnetic tape systems.
Step 1: Create S3 Bucket With Object Locks
We will create an S3 bucket To store our RDS backup data. after that, We will apply a lifecycle policy to transfer RDS data in the S3 glacier deep archive.
Give a unique name to our S3 bucket.

Turn on the versioning to store our all data in versions and we can rollback to the previous version.

-
Yes, enabling Object Lock on your S3 bucket can be a good idea if you’re storing important data like RDS backups. This feature can help protect your backups from being accidentally deleted or overwritten.
-> To enable object locks -> click on**Advanced Settings*-> checkEnableoption*

It's not enough to enable object locks you have to follow some instructions after the creation of the bucket.
*Go inside the bucket ->Properties->*Object lock -> click on Edit -> Choose Default retention mode: Governance
Default retention period: 10*(how many days you want to lock your objects)*

- After the creation of the S3 Bucket -> Click on that bucket name -> Click on Create Folder -> Make sure you give the folder name as rds_data because it's mentioned in our Lambda script -> Click on Create Folder

Step 2: Attach LIfeCycle Rule
Before attaching a lifecycle rule, you should know some things.
first, What are the lifecycle rules?
LifeCycle rules help you automate the process of moving your data between different storage classes and managing the lifecycle of your objects in a cost-effective manner
second, What are the storage classes?
S3 Standard: High durability, availability, and performance storage for frequently accessed data.
S3 Intelligent-Tiering: Optimizes costs by automatically moving data to the most cost-effective access tier, ideal for data with unknown or changing access patterns.
S3 Standard-IA and S3 One Zone-IA: Cost-effective storage for less frequently accessed data.
S3 Glacier Instant Retrieval and S3 Glacier Flexible Retrieval: For rarely accessed long-term data that does not require immediate access.
S3 Glacier Deep Archive: For long-term archive and digital preservation with retrieval in hours at the lowest cost storage in the cloud.
S3 Express One Zone: High-performance, single-zone storage for latency-sensitive applications, with data access speed up to 10x faster and request costs 50% lower than S3 Standard.
Let's start now.
we are attaching a lifecycle rule for transferring data from the S3 Standard to the S3 glacier deep archive.
Go to inside the new bucket ->Management-> Click on**Create lifecycle rule
Now give a name to the bucket and choose apply it to all objects in the bucket only If you want to apply changes to all the objects in the bucket.
In lifecycle rule actions choose option 1

Select the storage class from the menu. Enter the number of days after which it should move to Glacier/any storage class you choose.
For Ex: here I wrote 0 which means my objects will transfer immediately on that day. click I acknowledge and create rule.

Step 3: Create An IAM Role
We will create an IAM Role with specific permissions for creating RDS Instance snapshots and storing data in the S3 bucket.
Create an IAM Service Role by selecting the entity as AWS Service and the Use case as Lambda.

Give IAM Role following permissions and click Next
AmazonS3FullAccess
AmazonRDSFullAccess
AWSKeyManagementServicePowerUser
IAMFullAccess
This is not a good practice to give full access to all services. we are using it for testing purposes only.
Now in the Select trusted entities box paste the following trusted policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"export.rds.amazonaws.com",
"lambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
- Give a name to our Role and click on Create Role

Step 4: Create KMS Key
Don`t understand, do not worry I am here read the following definition now
Imagine you have a bunch of valuable items that you want to keep safe. So, you put them in a box and lock it. The key to this lock is very important because whoever has the key can open the box and access your valuables.
Note:- Please note that deleting a KMS key is a destructive and potentially dangerous operation. Once a KMS key is deleted, all data that was encrypted under the KMS key becomes unrecoverable. If you’re unsure, consider disabling the KMS key instead of deleting it.
Now, AWS Key Management Service (KMS) is like a key maker and manager. It creates and looks after these important keys for you. These keys are used to lock (encrypt) and unlock (decrypt) your digital valuables (data) in the AWS cloud.
I hope you understand now, so Let`s start
Go to KMS console -> Click on Create Key -> Let all the options default -> Just one thing if you want this key should work in all regions then select multi-region -> click Next

Give the key a name in the Alias box -> Description and Tags are optional -> Click on Next

Select Administrator User and allow it to delete the keys -> Next
Select the User and IAM Role that you want to give data encryption or decryption permissions. choose a previously created IAM Role and User with Administrator permissions. -> Next

preview the changes if everything looks good go on and click on Finish.
Step 5: Create Demo RDS Instance
Amazon Relational Database Service (RDS) is like a caretaker for your digital data. It’s a service provided by AWS that helps you set up and manage your databases in the cloud. RDS supports different types of databases, so no matter what kind of data you have, RDS can handle it.
Let's create a Sample MySQL RDS Instance.
Go to RDS console -> Click on Databases from left navigation pane -> then click on Create Database
Choose Easy Create -> MySQL (Because we are creating sample db)

- Choose Free tier -> give instance name in DB Instance Identifier -> give Master Username as admin -> Master Password as admin123 -> Click on Create Database
Note*: it will take 4-5 minutes to create RDS Instance*

Step 6: Create a Lambda Function
Now that we have the IAM Role, KMS Key, and S3 Bucket with lifecycle rule attached. we are ready to start the process of creating a Lambda function.
we are creating a lambda function which will perform the following tasks.
Create a New RDS Instance
Create a New RDS Instance Snapshot
Get New RDS Instance Snapshot ID
Export Snapshot To S3 Bucket
Go to Lambda Dashboard -> Click on the Create function
Select Author from scratch -> give the function a name -> choose Runtime as Python 3.8 -> use an existing role (choose the which we have created in step 3) -> Click on Create function

Scroll down -> in the IDE-like environment remove existing code -> now copy the following Lambda script and paste it there (use Ctrl+v) -> Click on the Deploy button.
For S3 Bucket Name:- [ Go to S3 console -> Buckets -> copy our bucket name ]
For IAM Role ARN:- [ Go to IAM Console -> search for the IAM Role we had created in step 3 -> click on role -> you can see role ARN -> copy role ARN ]
For KMS Key ARN:- [ Go to KMS console -> click on key -> copy key ARN ]
import boto3
from datetime import datetime
# CALLING ALL LAMBDA FUNCTIONS
def lambda_handler(event, context):
create_snapshot()
snapshot_id()
export_snapshot_to_s3()
return "All operations completed successfully"
# CREATE SNAPSHOT OF RDS INSTANCE
def create_snapshot():
rds = boto3.client('rds')
data = rds.describe_db_snapshots()
item = data["DBSnapshots"]
try:
for i in item:
if i["DBSnapshotIdentifier"] == "mysnap":
responce = rds.delete_db_snapshot(
DBSnapshotIdentifier = 'mysnap'
)
print("existing snapshot deleting....")
else:
response = rds.create_db_snapshot(
DBInstanceIdentifier = '<your-Instance-name>',
DBSnapshotIdentifier = 'mysnap'
)
print("Snapshot creation started. Waiting for 'available' state...")
waiter = rds.get_waiter('db_snapshot_completed')
waiter.wait(DBSnapshotIdentifier='mysnap')
print("Snapshot is now available....")
except Exception as e:
print(e)
create_snapshot()
# GET RDS INSTANCE LATEST SNAPSHOT ID
def snapshot_id():
rds = boto3.client("rds")
data = rds.describe_db_snapshots()
latest_snapshot = max(data['DBSnapshots'], key=lambda x: x['SnapshotCreateTime'])
id = latest_snapshot['DBSnapshotArn']
return id
snap_id = snapshot_id()
# RDS SNAPSHOT VERSIONING
current_time = datetime.now()
formatted_time = current_time.strftime('%d%m%Y%H%M')
# EXPORT RDS INSTANCE SNAPSHOT TO S3 BUCKET
def export_snapshot_to_s3():
rds = boto3.client('rds')
response = rds.start_export_task(
ExportTaskIdentifier=f'task-{formatted_time}',
SourceArn= snap_id,
S3BucketName='<your-S3-bucket-name>',
IamRoleArn='<your-IAM-Role-ARN>',
KmsKeyId='<your-KMS-Key-ID>',
S3Prefix='rds_data'
)
export_snapshot_to_s3()
- Click on Configuration -> General Configuration -> right side Edit button

Increase the Timeout to 5 minutes 0 Seconds -> Save (in that way our execution will not stop due to timeout)

Now you can test the function with the Test event you just have to give {} an empty curly bracket in JSON format and click on Test
I you encounter the below error then follow these instructions.
-> Go to IAM Console -> Left navigation pane Role -> Search for our Role -> Click on our Role -> Click on Trust relationship tab -> Click on Edit trust policy -> Change the following line in the code -> After that click on Update policy.
"service": "lambda. amazonaws.com" to "service: "export.rds.amazonaws.com"
Error:- botocore.errorfactory.IamRoleNotFoundFault: An error occurred (IamRoleNotFound) when calling the StartExportTask operation: The principalexport.rds.amazonaws.comisn't allowed to assume the IAM role arn:aws:iam::<aws a\c>:role/RDS-to-S3-full-access or the IAM role arn:aws:iam::<aws a/c>:role/RDS-to-S3-full-access doesn't exist.

While tesing you can see this kind of error it does not mean your lambda function get failed. so don`t worry. it successful and you can see the process of exporting snapshot has been started. I do not understand why it is hapenning if someone find the

Step 7: Create SNS Topic
Go to SNS Console -> Click Topic from left navigation pane -> Click on Create Topic.know more about SNS

Select Standard -> Give a name to our Snapshot -> Give Display name (optional-it will display 10 characters in SMS of it) -> Scroll down and Click on Create topic

Click on Publish massage

you will see the below page -> Give Subject name(optional) -> Write the massage in massage body you want to show in your SNS massage.

Create a subscription to SNS
- Click on Create Subscription

Choose the topic arn that we have created earlier -> Choose the Protocol that you want. now we will choose Email -> Give Endpoint as your Email/Gmail. -> Click on Create Subscription

Go to your Email provider app and you will see the email below. just click on Confirm Subscription after that you will subscription confimed massage


Step 8: Create a Destination For Lambda
- Come to the homepage of lambda -> Click on Add destination (it will trigger after completion of lambda function)

For Adding Destination -> Select Asynchronous Invocation -> Select On Success(if you want it should send a message after failure then choose On Failure) -> Destination type: SNS Topic -> In Destination select our new topic "Snapshot-export-topic" -> Click on Save
(this SNS topic will send a message after the successful completion of the lambda function)

Step 9: Create Trigger For Lambda Function
- Come to the homepage of lambda -> Click on Add Trigger

Search for CloudWatch EventBridge -> Select EventBridge -> Select Create a new rule -> Give description(optional)

Now Select Schedule Expressions and give your desired time with cron or rate expression then click on Add. To know more about expressions click here.
Note:- We are using rate expression for triggering the lambda function and it will trigger our lambda function every 5 minutes.
precautions:- After testing, delete the Lambda function to avoid unnecessary charges.

Cron Expressions

Rate Expressions

Step 10: Testing Lambda Function
We have given time of 5 minutes to trigger lambda so wait for 5 minutes.
After 5 minutes Go to RDS Console -> Snapshots -> Export to s3 Bucket

you can see the task is in Starting/In progress Status.
Note:- This task will take 30 to 60 minutes depending on DB backup data to export data from RDS to S3.

After completion of exporting data. Go to S3 Console -> Go inside our S3 bucket -> Click on folder rds_data -> Then you will see our task has been stored in the S3 bucket -> Click on the task and you will see data as you see in the below screenshot.

so that means we have successfully automated the process of exporting RDS data to S3 and now it will go into S3 Glacier because we have applied Lifecycle policy to it.
Step 11: Clean Up
Delete all S3 bucket objects then delete the bucket
Go to S3 Console -> Select Bucket -> Click on Empty -> type permanently delete -> Delete
Select Bucket again -> Click on Delete -> type bucket name -> Delete bucket
Delete our IAM Role if you want to
Go to IAM console -> Role -> Search for Role -> Select Role to delete -> Click on Delete -> Give Role name -> press Delete
Delete SNS Topic
Go to SNS Console -> Topics -> Select topic to delete -> Click on Delete -> type delete me -> press Delete
Delete RDS Instance with snapshots
Go to RDS Console -> Databases -> Action menu -> Delete -> Uncheck Create final snapshot and Retain automated backups -> Check acknowledgment -> type Delete me -> press Delete

Delete Lambda Fuction
Go to Lambda Dashboard -> Functions -> Action menu -> Delete -> type name of lambda function -> press Delete
Disable/Schedule to delete KMS key
Go to KMS Console -> Costumer-managed keys -> Select key -> keys action -> Select Disable/Schedule key deletion -> If you select Schedule key deletion so select how many days after the key should be deleted. (minimum 7) -> Press Schedule deletion
